行业 AI 产品落地难,难在两件事:通用能力别每个项目重写一遍、行业 know-how 别堆在通用框架里污染别的客户。combo agent 选择把这两件事在架构上一开始就分开。
TL;DR
| 问题 | 我们的回答 |
|---|---|
| 同一支团队怎么同时做三个行业的 AI 产品? | 平台层(通用)+ 应用层(行业),一份代码三套 variant |
| 通用能力升级,怎么不影响行业产品稳定性? | 三套 variant 单测分离 + 共享 e2e 流水线,平台层动 → 三处同时回归 |
| 行业 know-how 怎么不污染平台? | 文档与技能按 variant 子树隔离,运行时只加载本 variant 的应用层 |
| 客户数据怎么不跨租户? | 多租户物理隔离,不做跨客户的"行业基准"训练 |
行业 AI 落地的两难
我们见过的失败案例分两类:
**A 类:**通用 AI 助手 + 行业 prompt 模板。结果:客户拿到的是「ChatGPT 包了一层皮 + 一堆 system prompt」,专业问题答不上,术语不准,工作流不贴合。
**B 类:**为某个行业从零做一个产品。结果:业务跑通了,但下一个行业要做相同的事时,发现要把多 Agent 编排、上下文管理、记忆系统、技能调度全部重写一遍。
combo agent 的设计是:通用与行业必须在架构层切开,但又要在产品形态上整合好。
平台层做什么
平台层是 combo agent,提供与行业无关的基础能力:
| 能力 | 关键设计 |
|---|---|
| 多 Agent 任务编排 | Magentic-One 风格的 orchestrator,规划 / 执行 / 反思三段式 |
| 上下文管理 | 长会话窗口策略(默认 200K,可调)+ 智能压缩 + 双层记忆(STM/LTM) |
| 技能体系(Skill) | 可热插拔的能力单元;既能用社区生态(gstack / lark / wecom / docx / xlsx),也能写客户专属 |
| 会话与团队协作 | 多会话并行 / 选区编辑 / 一键共享会话给团队成员 |
| 多租户与渠道 | 飞书 / 企业微信 / 邮箱 / Web SDK 多入口;租户级数据物理隔离 |
| 代码索引三档 | 零索引 / 轻索引 / 重索引按需选择,匹配从临时审到全分支审的不同深度 |
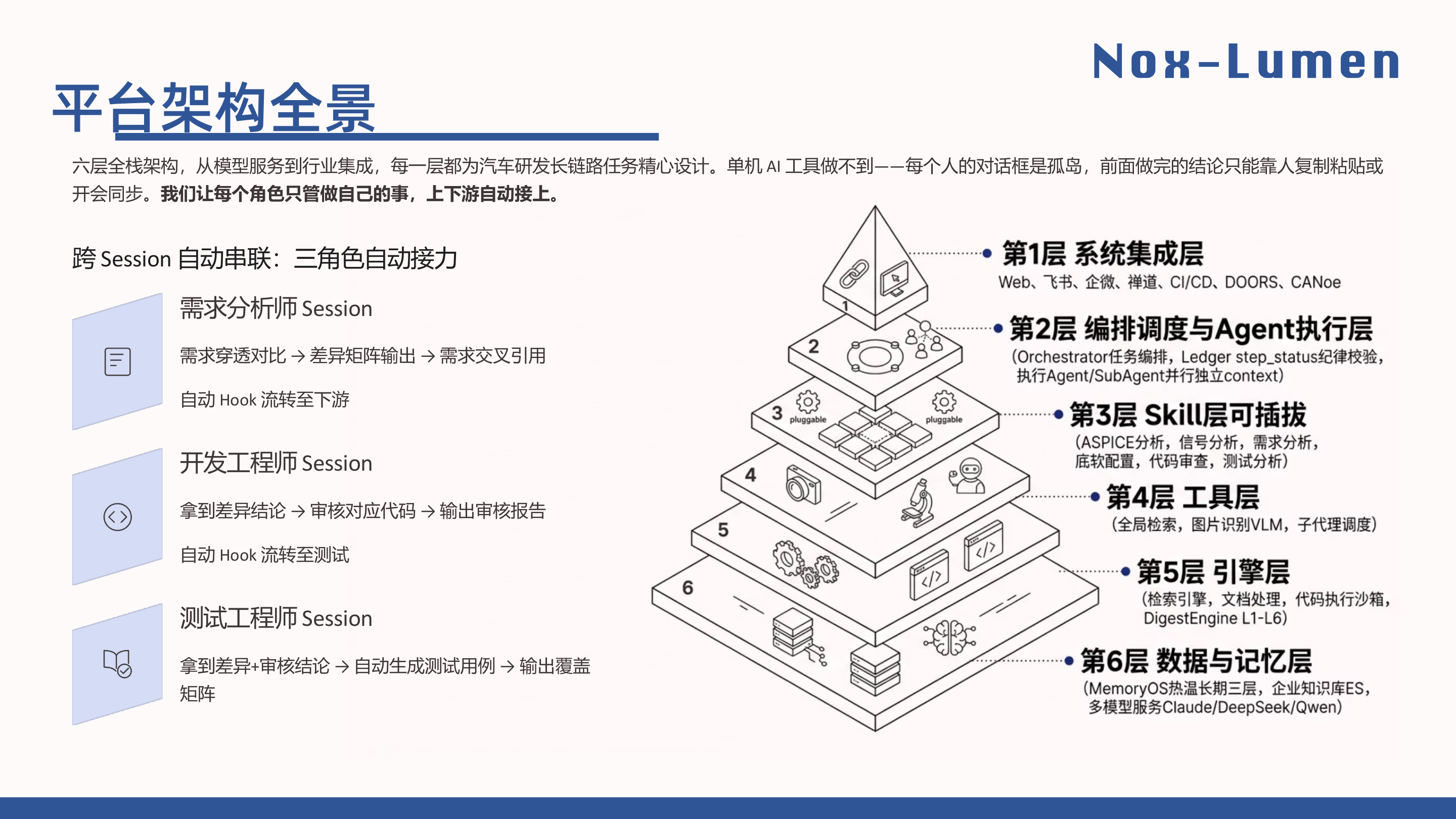
平台层通用能力详见 combo agent 使用说明书。
应用层做什么
每个行业一个 variant,在平台层之上沉淀该行业的专业 know-how:
| variant | 行业 | 应用层包含 |
|---|---|---|
| patent / xIPnex | 知识产权 | 专利代理师级 Agent、专利知识库、审查指南规则、说明书 / 权利要求 / 附图模板、novelty-search 跨源查新、patent-doc-formatter 专利局格式输出 |
| auto / Nox-Lumen Auto | 汽车研发 | ASPICE 4.0 工程闭环、MCAL 配置生成、CANoe / dSPACE / NI / ETAS 测试自动化、26262 / 21434 合规辅助、ARXML / DBC / A2L 多标准互转 |
| mfg / Nox-Lumen Mfg | 制造业 | 图纸自动审核、相似项目检索、双系统报价、Excel V1 模板对齐、客户隔离记忆库 |
应用层的核心是封装行业的工作流和专家规则。比如汽车的 automotive-process-analyzer 知道 V 字两侧的断点应该长什么样,专利的 patent-agent 知道独立权利要求和从属权利要求的结构约束,制造的 drawing-review 知道门窗工程里"红黄蓝问题"应该怎么分级。
同一份代码,三个官网
我们没有为每个行业 fork 一份代码,而是在同一份 codebase 上用 NEXT_PUBLIC_SITE_VARIANT 切换:
- 落地页文案:
messages/{locale}.{variant}.jsonoverlay 在通用messages/{locale}.json之上 - 品牌信息:
config/sites/{patent,auto,mfg}.ts配置 logo / 站点名 / 主色调 - 文档过滤:
app/source.ts内VARIANT_HIDE控制每个站只看到自己行业的子树 - 博客过滤:每篇文章 frontmatter 里写
variants: ["patent"]之类,运行时按 variant 过滤显示
结果就是:xipnex.nox-lumen.com、auto.nox-lumen.com、mfg.nox-lumen.com 三个域名,三份品牌、三份文档子集,但新模型上线、新通用 Skill 上线、平台 bug 修复只发一次。
为什么这么分
把通用与行业切开,对客户和我们都更好:
- 客户拿到的是为自己行业重新熟悉过术语 / 工作流 / 合规口径的产品,不是「通用 AI 助手 + 客户自己配 prompt」
- 我们升级模型 / 升级编排器,三个行业同步受益;写一个新行业,只新增 variant 不动平台
- 数据严格租户级物理隔离,不做跨客户的"行业基准"训练,客户数据主权不松动
- 平台层变更走共享 CI / 共享 e2e,回归在一处发生,三处自然受益
平台层的几个关键能力
代码索引三档
不是"裸 LLM 看 diff"——平台支持按场景选择索引深度:
| 档位 | 适合场景 | 平均出结论时间 |
|---|---|---|
| 零索引 | 临时审一个外包提交、一次性接管的旧代码 | 立等可取 |
| 轻索引(默认) | 日常 PR / MR / Gerrit change 审核 | 改一个文件秒级可搜 |
| 重索引 | 跨编译单元 / 全分支 / 全仓审、ASPICE 合规审、SOTIF 安全分析 | 初始化 10 分钟 ~ 小时级 |
ASIL-D 模块代码做"改这一行影响哪些下游"这种问题,必须开重索引档。详见 代码索引三档。
Graft 跨会话嫁接
每个会话都是独立上下文,但有时候需要"接力"——比如先做 ASPICE 追溯,再在另一个会话里基于追溯结果做变更影响分析。Graft 让后一个会话直接引用前一个会话的中间产物,避免重复跑。详见 Graft 技能。
bug-import:把团队历史 Bug 沉淀成 LTM
通过 bug-import 把客户 Jira / Polarion / 内部缺陷库的历史问题导入长期记忆,按"模块热点 / 跨模块模式 / 文件热点 / 反复根因"四维聚合。下次代码审查时,新提交命中历史模式会自动标 bug_pattern_match。详见 bug-import 技能。
部署形态
- 多模态接入:飞书 / 企业微信 / 邮箱 / Web SDK / HTTP API 多入口,同一个会话身份穿透
- 私有化部署:内网 / 国密合规,满足主机厂、Tier1、律所、制造头部企业的数据主权要求
- 持续托管:上线后我们继续养,客户不用招 AI 团队(详见 合作流程)
想看每个行业的具体落地
- 法律:xIPnex 当前进展 · 从一份交底书到一稿专利申请
- 汽车:Nox-Lumen Auto 当前进展 · ASPICE 工程闭环案例
- 制造:Nox-Lumen Mfg 当前进展 · 海外窗户工程客户落地
平台层完整能力清单见 combo agent 使用说明书,三个行业应用层完整清单见 solutions。
作者
Nox-Lumen Tech-team
发布日期
2026年5月14日